Developers working with reputed IT Company will explain the concept of Neo4J and how to use it in java development. The team is sharing this article with entire java development India and international community people. You can read and find the uses of Spring Data Neo4J in java development project.
Graph Database: Graph Database is database which store the data in the form graph.Neo4J store the data in the form Nodes, relationship and properties. Graph is similar to Table in RDBMS, Node is similar to row in RDBMS, and properties is similar to Columns of table, relationship similar to Joins in RDBMS.
Graph is set of Nodes, Node contains a set of properties, and also relation also contains set of properties to represent the data.
Like SQL is a query language for RDBMS, cypher is a query language for Neo4J.
Cypher is a declarative, SQL-inspired language for describing patterns in graphs visually using an asci-art syntax. Using Cypher we can retrieve, insert, update, and delete the data from graph database without specifying how to do it.
Node labels and properties of nodes are case-sensitive.
 Recently Facebook, Google, LinkedIn, and most of the social websites are using this Graph database for friends’ suggestions, posts, comments, likes etc.
Recently Facebook, Google, LinkedIn, and most of the social websites are using this Graph database for friends’ suggestions, posts, comments, likes etc.
Here KNOWS is the relationship between two nodes.
The relationship between Node 1 and Node 2 is having age property.
Downloading and installing Neo4J server:
We can download and install Neo4J server from https://neo4j.com/download/
After installing we can run the Neo4J server the below window will open:
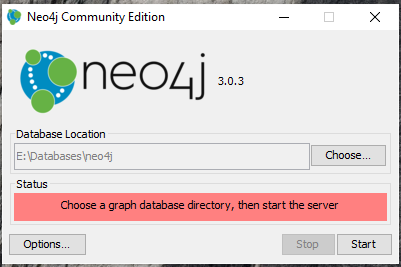
Where we can specify the Database location and we can click on start button to start the server, after successful start the below message it will show:
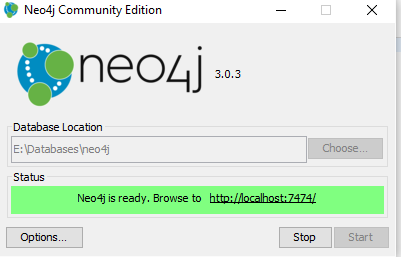
We can navigate to provided URL to get the stored data.
We need to use Cypher queries to get the Data present in Neo4j.
Integrating Neo4J with Spring Data framework:
Neo4J is providing Rest API for all of its operation.
Using Plain Rest Calls (without using any dependency):
To create a node without returning creating node:
EG: http://localhost:7474/db/data/transaction POST Request
The response will look like this:
Using this commit URL we need to invoke with payload to store the data.
Each transaction will have expiration time, before the expiration time we need to execute the POST Request.
Sample payload for commit request:
If we are not include the user-name and password we can add the credential to Configuration object.
We can add Credentials to configuration object in 2 ways.
1. We can create a org.neo4j.ogm.authentication.UsernamePasswordCredentials bean and we can pass user-name and password, we can add this credential object to configuration.
2. We can use overwrite method setCredentials, and we can pass user-name and password to it.
Technology:
Neo4J is one most popular NoSQL database for Graph based databases. It is completely developed using Java Language.Graph Database: Graph Database is database which store the data in the form graph.Neo4J store the data in the form Nodes, relationship and properties. Graph is similar to Table in RDBMS, Node is similar to row in RDBMS, and properties is similar to Columns of table, relationship similar to Joins in RDBMS.
Graph is set of Nodes, Node contains a set of properties, and also relation also contains set of properties to represent the data.
Like SQL is a query language for RDBMS, cypher is a query language for Neo4J.
Cypher is a declarative, SQL-inspired language for describing patterns in graphs visually using an asci-art syntax. Using Cypher we can retrieve, insert, update, and delete the data from graph database without specifying how to do it.
Node labels and properties of nodes are case-sensitive.
Advantage of Graph Database over RDBMS:
If the amount of the data is huge, if we want to query the joined data over the tables performance will be slow, but Graph database will provide the best performance.
Neo4J Features:
- CQL is a query language for Neo4J
- It supports ACID rules.
- It supports to give the content as JSON format
- It also provides Rest API for select, insert, update and delete the Graph data.
- It also supports Indexes using Apache Lucene.
- It provides a Node.Js dependent Java script Library for all operations.
Drawbacks:
- It does not support sharing.
- No support for ad hoc queries.
- Lack of client tool.
Neo4J system Characteristics:
- Disk based: Native graph storage engine with custom binary format
- Transactional: it supports JTA, XA(distributed transaction),2PC,deadlock detection.
- Scale up: It can scale up to Millions of Nodes/relations/properties on single VM.
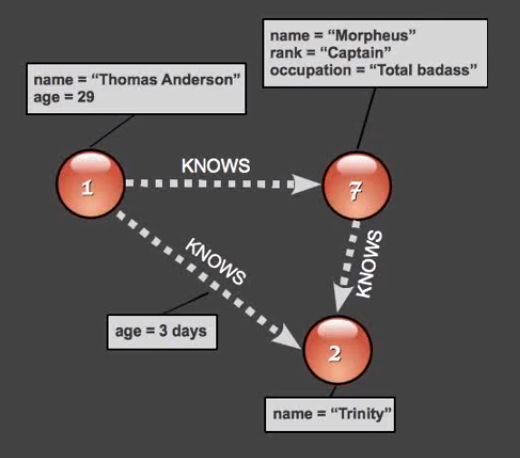
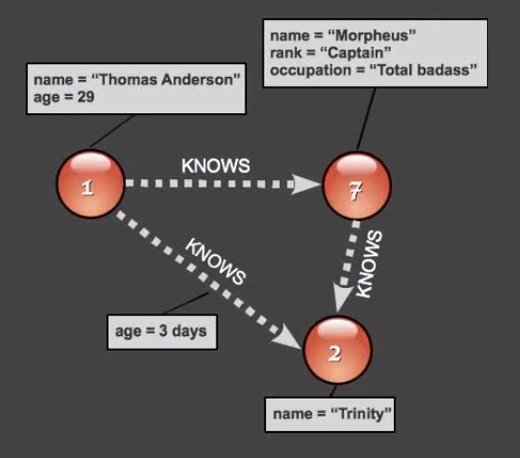
Sample structures of Nodes present in Neo4J:
Where 1, 2, 7 are the nodes.- Node 1 is having name and age properties.
- Node 2 is having only name property.
- Node 7 is having name, rank, and occupation properties.
Here KNOWS is the relationship between two nodes.
The relationship between Node 1 and Node 2 is having age property.
Downloading and installing Neo4J server:
We can download and install Neo4J server from https://neo4j.com/download/
After installing we can run the Neo4J server the below window will open:
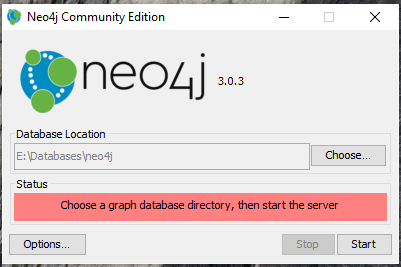
Where we can specify the Database location and we can click on start button to start the server, after successful start the below message it will show:
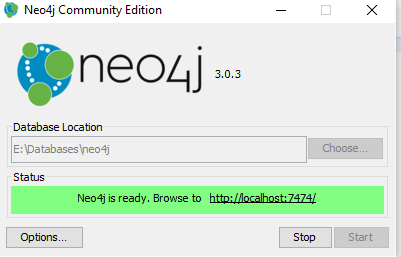
We can navigate to provided URL to get the stored data.
We need to use Cypher queries to get the Data present in Neo4j.
Some of the important queries we will use:
- Creating a Node with some properties:
CREATE (n: Movie{title:'Bahubali', released: 2016}) RETURN n
The RETURN n will return the created node, if we don’t specify any RETURN if will log Added 1 label, created 1 node, set 2 properties. - To list down all nodes:
MATCH (n) RETURN n
Where n is variable.
It will display all the nodes present in Neo4J.If you can closely observe we are getting the data having two labels Movie and Person. - To display the Nodes for a Node:
For example if we want to display only Nodes having label as Movie.
MATCH (n:Movie) RETURN n
- Adding relation between two Nodes:
MATCH (a:Movie {title:'Bahubali'}), (b: Movie {title:’ sultan'})
CREATE (a)-[r: FRIEND {location:'India'}] -> (b)
RETURN a,r,b
Integrating Neo4J with Spring Data framework:
Neo4J is providing Rest API for all of its operation.
Using Plain Rest Calls (without using any dependency):
To create a node without returning creating node:
- First we need to open transaction, the response will provide the commit URL, using commit URL to we can pass the payload to store the data.
EG: http://localhost:7474/db/data/transaction POST Request
The response will look like this:
{
"Commit": "http://localhost:7474/db/data/transaction/34/commit",
"Results": [],
"transaction": {
"expires": "Tue, 12 Jul 2016 18:04:49 +0000"
},
"errors": []
}
Using this commit URL we need to invoke with payload to store the data.
Each transaction will have expiration time, before the expiration time we need to execute the POST Request.
Sample payload for commit request:
{
"statements": [
{
"statement": "CREATE(n:Movie {title:'sultan',released:2017}) RETURN n",
"resultDataContents": [
"row",
"graph"
],
"includeStats": true
}
]
}
{
"results": [
{
"columns": [
"n"
],
"data": [
{
"row": [
{
"title": "sultan",
"released": 2017
}
],
"meta": [
{
"id": 10,
"type": "node",
"deleted": false
}
],
"graph": {
"nodes": [
{
"id": "10",
"labels": [
"Movie"
],
"properties": {
"title": "sultan",
"released": 2017
}
}
],
"relationships": []
}
}
],
"stats": {
"contains_updates": true,
"nodes_created": 1,
"nodes_deleted": 0,
"properties_set": 2,
"relationships_created": 0,
"relationship_deleted": 0,
"labels_added": 1,
"labels_removed": 0,
"indexes_added": 0,
"indexes_removed": 0,
"constraints_added": 0,
"constraints_removed": 0
}
}
],
"errors": []
}
Java Configuration required to connect to Remote Neo4J:
Publicstaticfinal String URL = System.getenv ("NEO4J_URL")!=null ? System.getenv ("NEO4J_URL"):"http://neo4j:sravan@localhost:7474";
@Bean
public org.neo4j.ogm.config.Configuration getConfiguration() {
org.neo4j.ogm.config.Configuration config = new org.neo4j.ogm.config.Configuration();
config
.driverConfiguration()
.setDriverClassName("org.neo4j.ogm.drivers.http.driver.HttpDriver")
.setURI(URL);
returnconfig;
}
If we are not include the user-name and password we can add the credential to Configuration object.
We can add Credentials to configuration object in 2 ways.
1. We can create a org.neo4j.ogm.authentication.UsernamePasswordCredentials bean and we can pass user-name and password, we can add this credential object to configuration.
EG: @Bean
public org.neo4j.ogm.config.Configuration getConfiguration() {
org.neo4j.ogm.config.Configuration config = new org.neo4j.ogm.config.Configuration();
config.driverConfiguration()
.setDriverClassName("org.neo4j.ogm.drivers.http.driver.HttpDriver")
.setURI ("http://localhost:7474")
.setCredentials(crendentials(userName, password));
return config;
}
2. We can use overwrite method setCredentials, and we can pass user-name and password to it.
Eg: @Bean
public org.neo4j.ogm.config.Configuration getConfiguration() {
org.neo4j.ogm.config.Configuration config = new org.neo4j.ogm.config.Configuration();
config.driverConfiguration()
.setDriverClassName("org.neo4j.ogm.drivers.http.driver.HttpDriver")
.setURI("http://localhost:7474")
.setCredentials(username,password);
return config;
}
Neo4J drivers:
Neo4J comes with two types of drivers.one which we can use for development (org.neo4j.ogm.drivers.http.driver.HttpDriver) and another is for embedded mode which we can use unit-testing purpose(org.neo4j.ogm.drivers.embedded.driver.EmbeddedDriver), but using N4o4J dependencies we EmbeddedDriver will not available. We need to add one more dependency:
<dependency>
<groupId>org.neo4j</groupId>
<artifactId>neo4j-ogm-embedded-driver</artifactId>
<version>${ogm-version}</version>
</dependency>
SessionFactory: Neo4J is implemented similar way of Hibernate using SessionFactory, and session. Whenever the session Factory is created it prepares the metadata which will shared to all session created using session Factory bean, it must scoped to application.
Creating sessionFacory Bean:
Spring Data Neo4J provides basic configuration in Neo4jConfiguration, we can extends this class to customize the configuration.
So, Neo4J configuration will look like this:
@NodeEntity: Identifies a domain entity as being backed by a node in the graph.This annotation is not needed if the domain entity's simple classname matches at least one of the labels of the node in the graph (case insensitive).
@GraphId is the annotation for specifying the primary key.
@Property: which is create a property on Node, it is an optional if we want to customize the property key then we can use this annotations.
@Convert: It is used to convert the value from Neo4J to type specified on field.
@Relationship: relationships with other Nodes, we need to specify the relationship name and direction either incoming or outgoing.
Entity will look like this:
And Repository will look like:
SessionFactory: Neo4J is implemented similar way of Hibernate using SessionFactory, and session. Whenever the session Factory is created it prepares the metadata which will shared to all session created using session Factory bean, it must scoped to application.
Creating sessionFacory Bean:
Public SessionFactory getSessionFactory() {
Return new SessionFactory (getConfiguration (), "movies.spring.data.neo4j.domain");
}
Integrating with Spring Data Neo4J:
Spring Data Neo4J has @EnableNeo4jRepositories annotation which will bootstrap the Neo4J Operations.Spring Data Neo4J provides basic configuration in Neo4jConfiguration, we can extends this class to customize the configuration.
Interacting with Neo4J Database:
- Like Hibernate we can use session for all CRUD operation
- Spring Data Neo4J provides Neo4jTemplate template class for CRUD operation.
- Like Spring Data CrudRepository Spring Data Neo4J is also providing one interface for all basic operation like save, update, delete, find queries, either we can follow the spring Data method Name convention so that the queries will generated by Spring Data or we can annotate the methods using @Query we can pass Cypher query to this annotation, whenever we call this method the specified Cypher Query is executed and it will return the results.
So, Neo4J configuration will look like this:
import org.neo4j.ogm.session.SessionFactory;
import org.springframework.boot.autoconfigure.EnableAutoConfiguration;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.ComponentScan;
import org.springframework.context.annotation.Configuration;
import org.springframework.context.annotation.Import;
import org.springframework.data.neo4j.config.Neo4jConfiguration;
import org.springframework.data.neo4j.repository.config.EnableNeo4jRepositories;
import org.springframework.data.rest.webmvc.config.RepositoryRestMvcConfiguration;
import org.springframework.scheduling.annotation.EnableScheduling;
import org.springframework.transaction.annotation.EnableTransactionManagement;
@EnableTransactionManagement
@Import(RepositoryRestMvcConfiguration.class)
@EnableScheduling
@EnableAutoConfiguration
@ComponentScan (basePackages = {"movies.spring.data.neo4j.services"})
@Configuration
@EnableNeo4jRepositories(basePackages = "movies.spring.data.neo4j.repositories")
publicclass MyNeo4jConfiguration extends Neo4jConfiguration {
publicstaticfinalStringURL = System.getenv("NEO4J_URL") != null ? System.getenv("NEO4J_URL") : "http://neo4j:sravan@localhost:7474";
@Bean
public org.neo4j.ogm.config.Configuration getConfiguration() {
org.neo4j.ogm.config.Configuration config = new org.neo4j.ogm.config.Configuration();
config
.driverConfiguration ()
.setDriverClassName("org.neo4j.ogm.drivers.http.driver.HttpDriver")
.setURI(URL);
returnconfig;
}
@Override
public SessionFactory getSessionFactory() {
ReturnnewSessionFactory (getConfiguration (), "movies.spring.data.neo4j.domain");
}
}
Creating entities for Neo4j:
Like @Entity for JPA, spring Data Neo4j has @NodeEntity to mark the class as an entity.@NodeEntity: Identifies a domain entity as being backed by a node in the graph.This annotation is not needed if the domain entity's simple classname matches at least one of the labels of the node in the graph (case insensitive).
@GraphId is the annotation for specifying the primary key.
@Property: which is create a property on Node, it is an optional if we want to customize the property key then we can use this annotations.
@Convert: It is used to convert the value from Neo4J to type specified on field.
@Relationship: relationships with other Nodes, we need to specify the relationship name and direction either incoming or outgoing.
Eg:@Relationship(type="ACTED_IN", direction = Relationship.INCOMING)
Entity will look like this:
@NodeEntity
publicclass Movie {
@GraphId Long id;
private String title;
privateintreleased;
private String tagline;
@Relationship(type="ACTED_IN", direction = Relationship.INCOMING) private Listroles;
public Movie() { }
//getter and setter
}
@RepositoryRestResource(collectionResourceRel = "movies", path = "movies")
publicinterface MovieRepository extends GraphRepository {
Movie findByTitle(@Param("title") String title);
@Query("MATCH (m:Movie) WHERE m.title =~ ('(?i).*'+{title}+'.*') RETURN m")
CollectionfindByTitleContaining(@Param("title") String title);
@Query("MATCH (m:Movie)<- a.name="" a:person="" ap="" as="" cast="" collect="" limit="" list="" m.title="" movie="" object="" return="" tring="">> graph(@Param("limit") intlimit);
}
Disqus Comments Loading..